Your Power BI model is fed by a data warehouse, and you’d like to make some reports, but now your Customer table has several entries for each customer instead of one. Then, you filter out the obsolete versions of customers, and you find that you’re missing transactional data and you can’t get Lifetime to Date (LTD) sales. What to do in this case?
As noted in my post, So, You’re Getting a Data Warehouse for Power BI…, ”
“The purpose of a data warehouse is historical analysis, and this shapes design decisions.” A slowly changing dimension is used to track changes over time for historical analysis. For example, analyzing sales in specific postal codes. For this kind of analysis, you want to use the postal code at the time and not the current postal code. But what if you want to see Lifetime to Date sales for customers according to current zip codes? Where do my loyal customers live now? I’ll get to that, but first: what exactly is a slowly changing dimension?
SCD Type 2
The most common type of slowly changing dimension is Type 2 (SCD Type 2 sounds like a disease, doesn’t it?). There are others, however, and there’s several ways to implement Type 2 (see Wikipedia for more). The main concepts I’ll be looking at are: (1) every version of the data gets a new row in the lookup, and (2) each row has an flag if it’s current or not. It could be true/false, yes/no, or 1/0. Each row also has a start and end date. For current records, end date is either null or something like 99991231.
About Surrogate Keys…
In a data warehouse, typically rows are assigned a surrogate key. This is the unique identifier for a row, and is how the historical data connects to the slowly changing dimension table. Because it’s used to tie the data together, I typically hide it from report consumers.
Handling slowly changing dimensions
I see several ways of using SCD for showing current state for operational reports or other reasons.
1. Add a column to your transaction table (aka fact table) with the current id and make the relationship with the SCD based on that. This can be done with a DAX calculated column or in Power Query. You could create a second, inactive relationship, between the SCD and the transaction table using the historical surrogate id column.
Below, I show how to do this using DAX and a copy of the lookup table. To begin with, load a copy of the lookup table to your model, making sure there are no relationships and hiding it from the canvas. You only need the external id, the surrogate, and the current flag in this table. Then, add a calculated column to your transaction table. This calculated column in the transaction table relies on the copy of the lookup to avoid circular reference.
CurrentSurrogateId =
// Calculated column. Add to transaction table.
VAR ThisId = Sales[SurrogateCustomerId]
VAR ThisCustomer =
CALCULATE (
MAX ( 'Customer (2)'[CustomerId] ),
'Customer (2)'[SurrogateCustomerId] = ThisId
)
RETURN
CALCULATE (
MAX ( 'Customer (2)'[SurrogateCustomerId] ),
ALL ( 'Customer (2)' ),
'Customer (2)'[CurrentFlag] = 1,
'Customer (2)'[CustomerId] = ThisCustomer
)![Customer lookup has a direct relationship with Sales transaction table via Customer[SurrogateCustomerId] and Sales[CurrentSurrogateId]. A copy of Customer table is a disconnected and hidden table used for LOOKUPVALUE().](https://p3adaptive.com/wp-content/uploads/2019/05/SCD-calculated-column-fact-power-bi.png)
2. Update all of the attribute columns in your lookup to the most current version. Paste this self-contained M code in the Power Query in Power BI or Excel to see the process. What this does is filter to the most recent rows and then merge in the full records to get the surrogate ids.
// Quick Fix SCD
let
Source =#table ( type table [Name = text, PostalCode = text, CustomerId = number, SurrogateCustomerId = number, CurrentFlag = number], { {"Joe Smith", "64114", 50, 1, 0}, {"Joe Smith", "20009", 50, 2, 0}, {"Joe Smith", "10454", 50, 3, 0}, {"Joe Smith", "64105", 50, 4, 1}, {"Ida Jones", "90210", 75, 6, 1}}),
#"Changed Type" = Table.TransformColumnTypes(Source,{{"Name", type text}, {"CustomerId", Int64.Type}, {"SurrogateCustomerId", Int64.Type}, {"CurrentFlag", Int64.Type}}),
T_Customer = #"Changed Type",
T_Current = Table.SelectColumns(Table.SelectRows(T_Customer, each ([CurrentFlag] = 1)),{"Name", "PostalCode", "CustomerId", "CurrentFlag"}),
#"Merge Surrogate CustomerId" = Table.NestedJoin(T_Current, {"CustomerId"}, T_Customer, {"CustomerId"}, "SurrogateCustomerId", JoinKind.LeftOuter),
#"Expanded Old SurrogateCustomerId" = Table.ExpandTableColumn(#"Merge Surrogate CustomerId", "SurrogateCustomerId", {"SurrogateCustomerId"}, {"SurrogateCustomerId"}),
#"Removed Columns" = Table.RemoveColumns(#"Expanded Old SurrogateCustomerId",{"CurrentFlag"})
in
#"Removed Columns"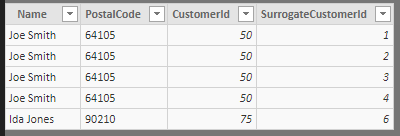
3. Snowflake lookup. You could reference the SCD and create a new query filtered only to current versions. Create a relationship between this table and the SCD table. Create a relationship between the SCD and the transaction table. In the SCD version, you only need the two columns for the ids. Load both tables to the model and hide the SCD version.
![Snowflake solution. Customer only has current records with external CustomerId. Snowflake table has external CustomerId and SurrogateId. Sales has CurrentId. Relationships: 1 to many between Customer[CustomerId] and Snowflake[CustomerId]; 1 to many between Snowflake[SurrogateId] and Sales[SurrogateId].](https://p3adaptive.com/wp-content/uploads/2019/05/SCD-Snowflake-lookup-power-bi-2.png)
Advantages of each method for handling SCD
The first approach using calculated columns is the most comprehensive. It preserves changes for historical analysis. It does require loading a copy of the lookup table in memory. And it adds a column to the transaction table. Using DAX puts the configuration at the report level, so this would need to be done for every report. The second approach using Power Query is quick and simple. Since it’s in Power Query, it can be created as a dataflow for multiple reports. It doesn’t involve duplicating a table, but it does lose the historical data from the model. The third approach keeps the historical data along with the current data, but does add a snowflake relationship, which may impact the performance of calculations when the report is viewed.
Sample Data
// Customer Source Data
let Source = #table ( type table [Name = text, PostalCode = text, CustomerId = number, SurrogateCustomerId = number, CurrentFlag = number], { {"Joe Smith", "64114", 50, 1, 0}, {"Joe Smith", "20009", 50, 2, 0}, {"Joe Smith", "10454", 50, 3, 0}, {"Joe Smith", "64105", 50, 4, 1}, {"Ida Jones", "90210", 75, 6, 1}})
in
Source
// Sales Source Data
let
Source = #table( type table [SurrogateCustomerId=Int64.Type, Amount= Currency.Type], { {1, 100000} ,{1, 500000}, {2, 10000}, {1, 20000}, {3, 5000}, {4, 50}, {6, 3} } )
in
SourceWhat do you think?
Which way looks best to you? Are there benefits and drawbacks I’ve missed? Maybe you have a better way. Let me know!
Where It’s At: The Intersection of Biz, Human, and Tech*
We “give away” business-value-creating and escape-the-box-inspiring content like this article in part to show you that we’re not your average “tools” consulting firm. We’re sharp on the toolset for sure, but also on what makes businesses AND human beings “go.”
In three days’ time imagine what we can do for your bottom line. You should seriously consider finding out 🙂
* – unless, of course, you have two turntables and a microphone. We hear a lot of things are also located there.
