Usability
Can your data model (Power Pivot or Power BI) easily be used by 100s of users? Is your model fairly intuitive to understand for the end-user even with little or no training?
Usability may be the key to achieving the Self-Service BI nirvana.
The very first Power Pivot model that I had designed…
| Number of users I expected to use my first Power Pivot Model | 1 (myself) |
| Number of users that actually ended up using the model | 600+ |
I learnt my lesson the hard way. The one-audience data model was filled with oddities that was not always easy for end users to understand. I ended up doing a lot of video tutorials (now you know how I got good at video ![]() , check out our YouTube channel).
, check out our YouTube channel).
Now when I design a model for any client, I design with usability in mind. Such that perhaps not right away, but at some point 100s of users can use the BI Model for Self-Service BI. They can easily navigate the model to create their own Reports and Dashboards (in Excel or Power BI).
I use a few techniques when designing for usability; good Data Modeling (star schema), naming conventions, use of Perspectives, automated Data Dictionary (documentation) are some that I lean on.
In this blog post, I would illustrate one scenario where, some would argue I go to great lengths to make the model more usable. As you will realize, it is well worth it.
GOAL: Out goal is to combine two data tables – Sales and Budget – which are at varying granularity, but without the use of a an extra lookup table.

GOAL: Combine Sales and Budget without creating a “Subcategory” Lookup table
Jump to section:
Setup and the Classic Solution
Usability Issues with the Classic Solution
Elegant Solution
Results
Epilogue: Single Data Table with Differing Granularity
Need help designing your BI Model? Check out our Training and Consulting Services
Setup and the Classic Solution
In our book, Chapter 18 Multiple Data Tables – Differing Granularity, we show how you can combine Data Tables of differing granularity.
(You have a copy of our book, right? Hmmm…why would you wait to buy the #1 bestselling Power BI book on the market, Carpe diem my friend!).
Grain or granularity is a fancy word, which simply means what one row of data represents. For example in our data set:-
- Sales – is at a Daily and Product SKU (Individual Product or Product Key) level granularity
- Budget – is at a Monthly and Product SubCategory level granularity

Sales Table at grain – ProductKey, Date

Budget Table at grain – Product SubCategory and Month
You would encounter this pattern frequently when working with real world data sets – Data tables of differing granularity. And the book already shows you how to solve this using a shared Lookup table.

Sales and Budget linked by a newly created SubCategory Lookup Table
Creating a shared lookup table, lets you:
- Slice and dice your Sales and Budget numbers using any of the shared lookup tables (Calendar, SubCategory in this case)
- Define “Hybrid” measures which do math across the two data tables (e.g. Variance to Budget, or VTB = [Total Sales] – [Total Budget])

Slice and dice Sales and Budget using Lookup Tables and define “Hybrid” measures
You would encounter this pattern frequently when working with real world data sets – Data tables of differing granularity.
Usability Issues with the Classic Solution
When I think of Data Modeling, usually I have two criteria in mind – Performance and Usability. Let us consider these for the problem at hand:
(Data modeling best practices are sprinkled throughout our book. I also wrote an article which summarizes the key best practices: Data Modeling for Power Pivot and Power BI).
- Performance: Having a cascading Lookup table (SubCategory) with just one or two columns is generally inefficient. But performance is not our main criteria here.
- Usability: With the Classic solution, you end up with the “SubCategory” column in two places – in Products table and SubCategory table. And users are expected to remember to use the right SubCategory column.
– Use SubCategory[SubCategory] when using measures on [Budget] or hybrid measures
– Can use Product[SubCategory] when not using [Budget] related measures
If you or any user using the model to create Pivots/Reports uses the Category/SubCategory from the “wrong” table, then they can get unexpected results (see image below). You could hide the Category/SubCategory columns from the Product table, but that only feels like a hack.
– Category/SubCategory are Product attributes and logically belong in the Product table
– For users that do not care about [Budget] table and would never use those measures, this feels like an additional burden for them to find the Category/SubCategory in a separate table.

You always need to remember to use the Category/SubCategory fields from the “right” table, else you may not get the correct results
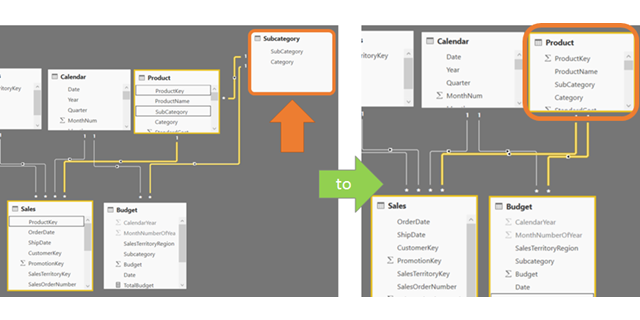
Elegant Solution
Here is how we can go about combining the Products and the newly created SubCategory table for a more usable and elegant solution. I have highlighted the key steps, you can examine the solution file to go step by step in the Power BI Query.
Note: Don’t be scared of the M code, 99% of these steps were generated using the Query ribbon – I have included those screenshots as well.
1. Create a SubCategory Lookup Table
Step1_BuildSubCategoryTable = _Product,
#"Removed Other Columns" = Table.SelectColumns(Step1_BuildSubCategoryTable,{"SubCategory", "Category"}),
#"Removed Duplicates" = Table.Distinct(#"Removed Other Columns", {"SubCategory"}),
#"Filtered Rows" = Table.SelectRows(#"Removed Duplicates", each ([SubCategory] <> null)),
SubCategoryTable = #"Filtered Rows",

Steps to create a SubCategory Lookup Table (click to enlarge)
This is so far identical to how we built the SubCategory Lookup Table in the classic solution.
2. Append Products and SubCategory Table
Step2_AppendTables = _Product,
#"Appended Query" = Table.Combine({Step2_AppendTables, SubCategoryTable}),

Append Queries is available on the Query ribbon interface
In the new appended table, the ProductKey is null for all rows coming from the SubCategory table.

ProductKey now has null values for the rows coming from SubCategory Lookup
This won’t do for a Lookup table (key used to create relationship cannot contain null values), thus we create a new key column.
3. Create New Product Key
#"Added Index" = Table.AddIndexColumn(#"Appended Query", "NewProductKey", 1, 1),

Add Index Column is available on the Query ribbon interface
Now we have a unique key for our appended table.

Now we have a NewProductKey that we could use
4. Update Sales and Budget Tables with New Product Key
All that’s left is to go back to our Data tables – Sales and Budget, and update those to use the NewProductKey.
The steps below are for updating Sales table; Budget table would be updated on similar lines to add the NewProductKey.
Step4_UpdateProductKey = #"ShiftYear to 2016",
#"Merged Queries" = Table.NestedJoin(#"Step4_UpdateProductKey",{"ProductKey"},Product,{"ProductKey"},"NewColumn",JoinKind.LeftOuter),
#"Expanded NewColumn" = Table.ExpandTableColumn(#"Merged Queries", "NewColumn", {"NewProductKey"}, {"NewProductKey"}),
#"Removed Columns" = Table.RemoveColumns(#"Expanded NewColumn",{"ProductKey"}),

Steps to pull in the NewProductKey into our Sales table (click to enlarge)
BONUS CHALLENGE: You can try generating NewProductKey in such a way that the Sales table would not need to be updated with a New Product Key. You would only need to worry about the Budget table.
I can think of a few ways to accomplish that. Up for the challenge? Modify our provided file and post a link to your solution file in comments.
Final Step: Link Sales and Budget to new Products Table
Next, you can link both the Sales and Budget data table to our new Products table using the NewProductKey column!

Sales and Budget linked by a Product Table, even though Budget is set at SubCategory
Results
We do not need to worry about using the right table for the right occasion (based on the measures being used). Furthermore, the Category, SubCategory fields – which are Product attributes – are found in the Products table, which would make more intuitive sense for end users.

Our new model is more user friendly: Product Category/SubCategory can be used to view both Sales & Budget
Epilogue: Single Data Table with Differing Granularity
The differing granularity problem not only occurs when multiple data tables are involved (e.g. Sales and Budget), but can also occur within a single data table. For example, Sales can record transactions at different grain of Geography (Territories table in our model).
- Some Sales transactions at the lowest granularity (Region in our case)
- Some Sales transactions at a higher granularity (e.g. Country). This can occur in a scenario where the deal was made, let’s say with the Government of a Country. Then ‘Country’ is the only level of information available.
This can be addressed using a similar approach as outlined above to build a Geography/Territory lookup table at a different grain. If interested in such a problem, leave us a comment and we’ll try to cover this in a follow up blog post.
Download Solution File: Usability_PBIX_Files.zip
Power On!
-Avi Singh